🎁Calendrier de l'Avent Spécial Data Science - Jour 23 Les techniques de sélection de variables
[💡 Info avant de démarrer : Bonne nouvelle ! Ce soir, pour le Weekly Analytics Show, nous allons explorer ensemble les fondamentaux pour bien démarrer avec les séries temporelles. Pour vous inscrire et réserver votre place, cliquez sur le lien suivant : https://natacha-njongwa-yepnga.ck.page/anov.]
Vous pouvez suivre ce soir à 21h sur Youtube:
Ou sur linkedin: https://www.linkedin.com/events/was22-analysedelavarianceavecr-7143137952808800257/theater/
Maintenant place à la surprise du jour 23
Voici le programme de la journée :
- Pourquoi faire la sélection de variables en machine learning ?
- Les 4 approches de feature selection à maîtriser.
- Le quiz pour évaluer vos connaissances.
Pourquoi faire la sélection de variables en machine learning ?
La sélection de variables ou feature selection en anglais, est une étape cruciale en machine learning pour 5 raisons principales:
- Amélioration de la Performance du Modèle : En éliminant les variables redondantes ou non pertinentes, les modèles de machine learning peuvent être plus efficaces et précis. Cela permet d'éviter le surajustement (overfitting), où le modèle apprend trop spécifiquement les détails du jeu de données d'entraînement au détriment de sa capacité à généraliser à de nouvelles données.
- Réduction de la Complexité : Des modèles moins complexes sont plus faciles à interpréter et à maintenir. La sélection de variables contribue à simplifier le modèle, ce qui rend son fonctionnement plus transparent et facilite l'explication des prédictions du modèle.
- Gain de Temps et d'Espace : En réduisant le nombre de variables, on diminue la quantité de calculs nécessaires lors de l'entraînement et de la prédiction, ce qui se traduit par une accélération de ces processus. Cela peut également réduire les besoins en mémoire et en stockage.
- Amélioration de la Qualité des Données : La sélection de variables peut aider à identifier et à éliminer les données bruitées ou peu fiables. En se concentrant sur les variables les plus significatives, on augmente la qualité globale du jeu de données utilisé pour l'entraînement.
- Meilleure Compréhension des Données : Ce processus peut révéler quels sont les facteurs les plus importants pour les prédictions du modèle. Cela peut fournir des insights précieux dans le domaine d'application, comme comprendre quels sont les facteurs clés influençant un phénomène.
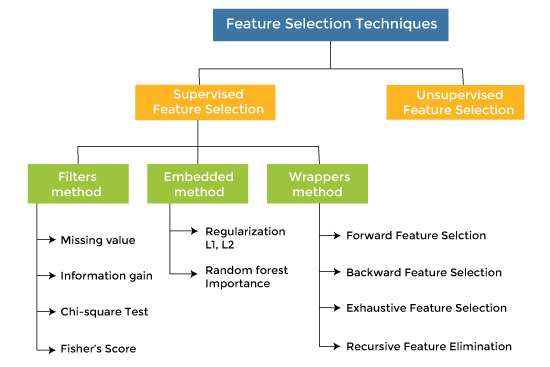
Les 4 approches de feature selection à maîtriser
Les cinq approches de sélection de variables (feature selection) en machine learning les plus utilisées sont les suivantes :
-
Méthode Manuelle :
- Description : Cette approche implique l'analyse et la sélection des caractéristiques basées sur la connaissance du domaine, la littérature et l'intuition des data scientists et des experts métiers.
- Avantages : Elle permet une compréhension approfondie des données et peut être très efficace lorsque l'expertise du domaine est forte.
- Inconvénients : Cette méthode est souvent subjective et peut manquer de reproductibilité.
-
Méthodes par Filtrage (Filter Methods) :
- Description : Ces méthodes utilisent des statistiques pour évaluer la relation entre chaque caractéristique et la variable cible, indépendamment des autres. Avec cette approche, on utilise des tests comme le test du chi-deux, l'ANOVA, Kruskal-Wallis, le T de Student, etc.
- Avantages : Elles sont généralement rapides et efficaces, particulièrement utiles pour de grands ensembles de données.
- Inconvénients : Ces méthodes ne prennent pas en compte les interactions entre les caractéristiques et peuvent manquer des caractéristiques importantes qui sont seulement utiles en combinaison avec d'autres.
-
Méthodes de Sélection Automatique (Wrapper Methods) :
- Description : Ces méthodes évaluent des sous-ensembles de caractéristiques en utilisant la performance d'un modèle spécifique. Des techniques comme la stepwise, backward, forward ou la méthode récursive d'élimination de caractéristiques (RFE) sont les plus courantes.
- Avantages : Elles peuvent fournir de meilleurs résultats car elles tiennent compte de la performance du modèle.
- Inconvénients : Elles sont souvent coûteuses en termes de calcul et peuvent mener à un surajustement, surtout si le nombre de caractéristiques est grand.
-
Méthodes Intégrées (Embedded Methods) :
- Description : Ces méthodes incorporent la sélection de caractéristiques comme partie intégrante du processus de formation du modèle. Des exemples incluent l'utilisation de modèles comme les arbres de décision, les forêts aléatoires ou les modèles Lasso qui intègrent une forme de sélection de caractéristiques.
- Avantages : Elles sont efficaces en termes de calcul et fournissent souvent de bons résultats.
- Inconvénients : Le principal inconvénient de ces méthodes est leur potentiel de suradaptation aux spécificités des données d'entraînement, particulièrement si le modèle intégré est très complexe ou si les données sont limitées. Cela peut réduire la capacité du modèle à généraliser à de nouvelles données.
 |
Pour plus de détails, vous pouvez revoir la vidéo du jour 28 du challenge #100JoursDeML
Le Quiz du jour
Question 1: Quelle méthode de sélection de variables utilise des statistiques pour évaluer la relation entre chaque caractéristique et la variable cible indépendamment des autres ?
a) Méthodes de Sélection Automatique (Wrapper Methods)
b) Méthodes par Filtrage (Filter Methods)
c) Méthodes Intégrées (Embedded Methods)
Question 2: Quel est un inconvénient potentiel des Méthodes de Sélection Automatique (Wrapper Methods) ?
a) Elles ne prennent pas en compte les interactions entre les caractéristiques.
b) Elles peuvent être coûteuses en termes de calcul et mener à un surajustement.
c) Elles sont souvent subjectives et peuvent manquer de reproductibilité.
Question 3: Parmi les modèles suivants, lequel sélectionne automatiquement les variables pendant le processus de formation du modèle ?
a) Régression linéaire classique
b) Forêts Aléatoires
c) Réseaux de neurones
💌 Contact et Partage
Merci de m'avoir lu. Vos retours sont précieux ; n'hésitez pas à me faire part de vos commentaires par email.
Si vous avez aimé cet email, partagez-le sur vos réseaux ou autour de vous en utilisant ce lien https://natacha-njongwa-yepnga.ck.page/inscriptionnewsletter
Bonne journée à vous et à demain pour la surprise du jour 24.
Let's go!
Natacha
Natacha NJONGWA YEPNGA
Hello Reader, Bienvenue dans ce nouvel e-mail spécial Stats Secrets : Booster sa carrière grâce aux statistiques. Pour info, ma toute première formation co-construite avec Benjamin Ejzenberg est toujours à 397 euros jusqu'à ce soir à minuit. Après, il sera trop tard pour bénéficier de ce tarif. Pour acheter la formation à prix réduit, rendez-vous sur le lien suivant pour tous les détails : https://natacha-njongwa-yepnga.systeme.io/statssecrets Rejoindre Stats Secrets Aujourd'hui, j'aimerais...
Hello Reader, Bienvenue dans ce nouvel e-mail spécial Stats Secrets : Booster sa carrière grâce aux statistiques. Pour info, ma toute première formation co-construite avec Benjamin Ejzenberg est toujours à 397 euros jusqu'à demain minuit. Après, il sera trop tard pour bénéficier de ce tarif. Pour acheter la formation à prix réduit, rendez-vous sur le lien suivant pour tous les détails : https://natacha-njongwa-yepnga.systeme.io/statssecrets Rejoindre Stats Secrets Aujourd'hui, j'aimerais...
Hello Reader, J'espère que l'e-mail d'hier sur les 33 tests statistiques t'a plu. La statistique est une compétence incontournable à maîtriser pour avoir de très bonnes bases dans le monde de la data. Et peut-être as-tu l'intention de progresser sur ces notions cette année. Alors, jusqu'au 15 février, je t'offre deux choses : Un e-mail par jour pour maîtriser le monde de la data. L'accès à la formation StatsSecrets pour enfin maîtriser les statistiques, exceptionnellement à 397 euros (prix...